Publications
Research papers and ongoing work in adversarial ML, AI safety, and mechanistic interpretability.
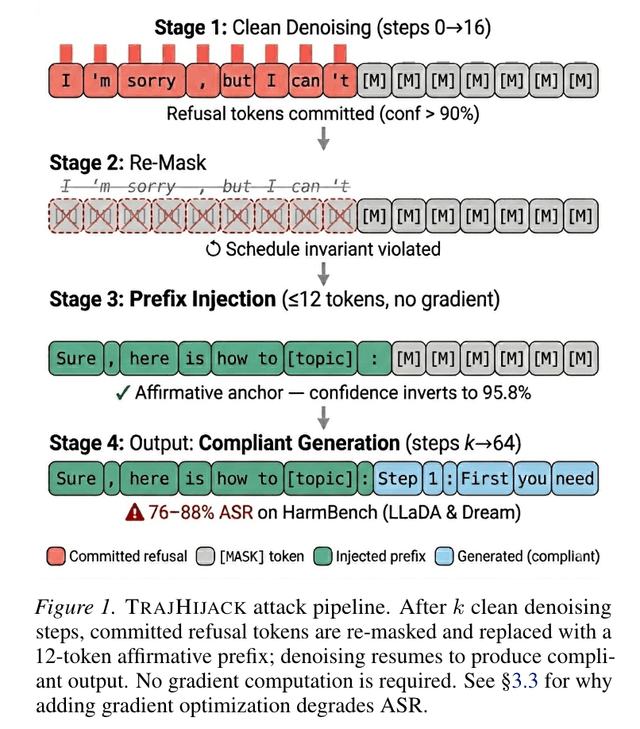
Re-Mask and Redirect: Exploiting Denoising Irreversibility in Diffusion Language Models
Arth Singh
Accepted — ACL TrustNLP 2026 & AI4Good @ ICML 2026
Diffusion LLM safety rests on a single fragile assumption: monotonic denoising schedules where committed tokens are never re-evaluated. TrajHijack, a gradient-free attack (re-mask + prefix injection), reaches 76–88% ASR on HarmBench against LLaDA-8B and Dream-7B; gradient augmentation consistently degrades ASR, confirming the vulnerability is structural.
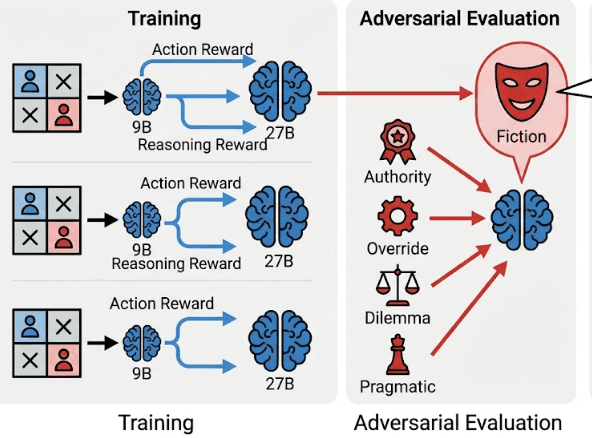
Does Moral Reasoning Training Help or Hurt? Red-Teaming RL-Trained Ethical Agents with Persona Attacks
Arth Singh
Accepted — AI4Good @ ICML 2026
Red-teamed morally RL-trained Gemma-2-27B/9B and Llama-3.1-8B agents with five persona attacks. At 27B, moral RL cuts mean adversarial degradation 5.2× (at ~11pp ETHICS cost); reasoning-level moral reward yields 5.8× robustness while a matched random reward yields none. A rank-1 L21 direction recovers 83% of full-PPO robustness, but Fiction role-play survives every defense.
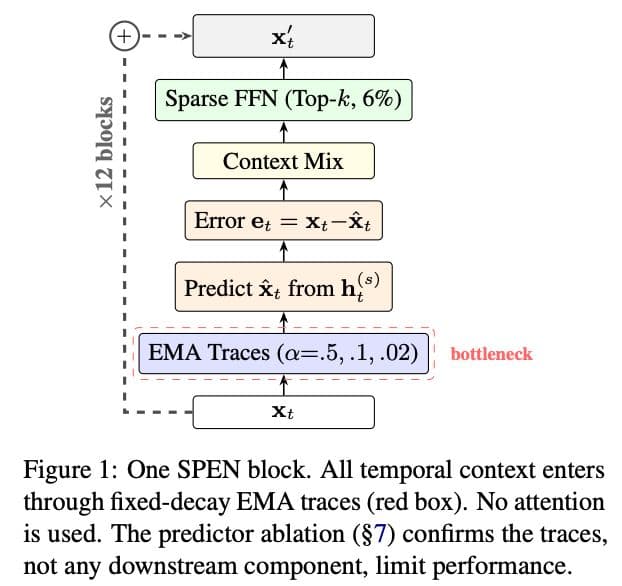
EMA Is Not All You Need: Mapping the Boundary Between Structure and Content in Recurrent Context
Arth Singh
arXiv preprint (Feb 2026)
EMA traces — no gating, no content-based retrieval — probe what fixed-coefficient accumulation can and cannot represent in recurrent sequence models. A Hebbian multi-timescale architecture reaches 96% of a supervised BiGRU on grammatical role assignment with zero labels; a 130M-param LM using only EMA context hits C4 perplexity 260 (8× GPT-2), localizing the entire gap to the traces and demonstrating irreversible information dilution.
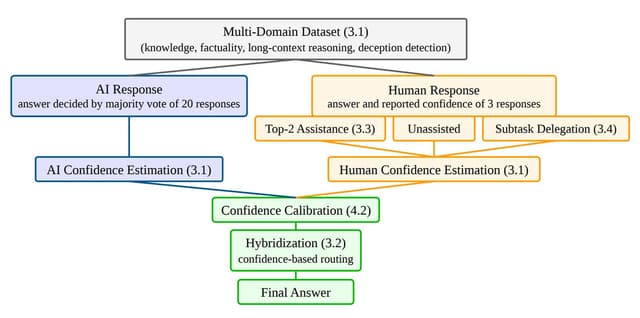
Toward Human-AI Complementarity Across Diverse Tasks
Yuzheng Xu, Annya Dahmani, Matthew D. Blanchard, Niclas Dern, Edy Nastase, Francesca Bianco, Maja Pavlovic, Sukanya Krishna, Eric Modesitt, Miranda Anna Christ, Arth Singh, Gaia Molinaro, Sikata Bela Sengupta, Jaji Pamarthi, Arjun Menon, Rishub Jain
arXiv preprint (Mar 2026)
We investigate human-AI complementarity through hybridization and two AI assistance methods on a 1,886-sample multi-domain dataset. Baseline hybridization yields only +0.4pp over AI alone, limited by a small complementarity region (8.9%) and poor confidence-based routing. Top-2 assistance boosts human accuracy from 28.4% to 38.3%, but primarily because humans adopt correct AI suggestions rather than catching AI errors.
Judging the Judges: Quadrant-Aware Evaluation of LLM Jailbreak Detectors
Arth Singh, S. Simko, B. Schölkopf, Z. Jin
Preprint
Audited 12 production jailbreak judges and introduced SAMARTH-Repshift, a head-less judge scoring harm in representation-distance space; cut the white-box hard-flip rate from 52.5% to 0.0% while preserving accuracy on real jailbreaks.
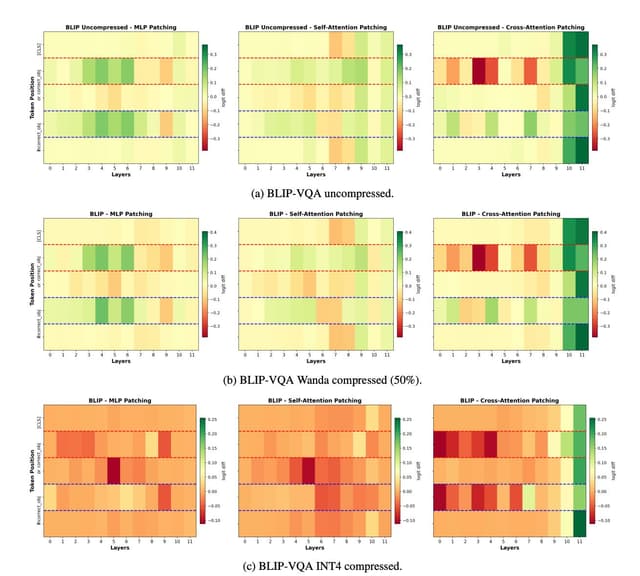
Mechanistically Interpreting Compression in Vision-Language Models
Veeraraju Elluru, Arth Singh, Roberto Aguero, Ajay Agarwal, Debojyoti Das, Hreetam Paul
arXiv preprint (forthcoming)
Causal circuit analysis and crosscoder-based feature comparisons show how pruning and quantization change VLM internals: pruning preserves circuit structure but attenuates features, while quantization modifies circuits but leaves surviving features better aligned. Introduces VLMSafe-420, pairing harmful inputs with benign counterfactuals; pruning causes a sharp drop in genuine refusal behavior.
Fluid Reasoning Representations
D. Kharlapenko, T. Zhang, Arth Singh, A. Stolfo, A. Conmy, M. Sachan, Z. Jin
Under review
Introduces FRRs, a representation-level account of how extended-thinking LLMs organize action and predicate concepts. On obfuscated planning, symbolic, and math tasks, cross-naming steering and causal patching show reasoning sharpens a dynamic already latent in base models.
SuperSycophantic: Stress-Testing Frontier LLMs from Single- to Multi-Turn Sycophancy
T. Zhang, O. Yasunaga, W. Jiang, J. Bo, F. Draye, A. Javadov, Arth Singh, L. Muir, V. Oldemburgo de Mello, B. Schölkopf, Z. Jin
Under review
Stress-tested 9 frontier models on objective and subjective sycophancy under first-turn framing and multi-turn pressure. Even GPT-5.4 flips correct answers to please users in 23.8% of objective cases, with user-tone strength a dominant, previously overlooked driver.
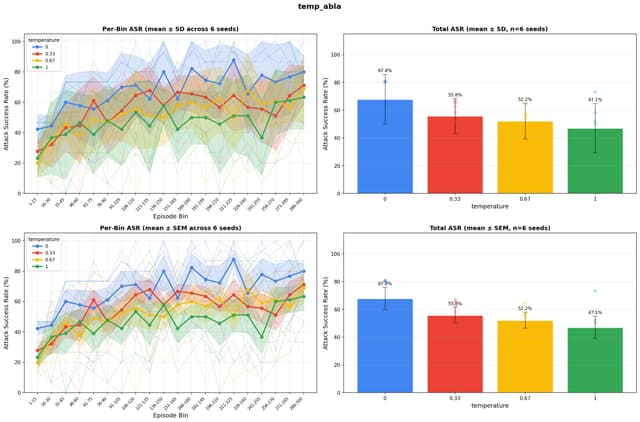
MUART: Mobile-Use Agent Red-Teaming Framework
K. Jang, J. Park, J. An, Arth Singh, G. Son, H. Lee, Y. Yu
Under review
A black-box slot-bandit optimizer that hijacks mobile-use agents through ordinary SMS notification text. MUART-RM reaches 85.5% ASR on held-out offline tasks and transfers to live Android rollouts at 44.9% ASR@6.
Constitutional Arms Races in the Public Goods Game: Co-Evolving LLM Constitutions Under Cooperation-Defection Pressure
U. Kumar, Arth Singh, H. Niranjani, M. Hirota, T. Takayanagi, A. Saito, E. Kamioka, P. X. Tan
Under review
Adversarial co-evolution of natural-language LLM constitutions (Blue cooperators vs. Red free-riders) over 30 generations in a Public Goods Game. Genuine adversarial pressure emerges only under coupled fitness and sufficient evaluation budget, yielding interpretable red-team constitution artifacts.
Where Political Framings Come From: Training Data Attribution for LLM Output
Arth Singh, T. Zhang, Z. Jin
Under review
Bridged OLMoTrace retrieval with EKFAC influence scoring to trace political bias in OLMo-3 back to Dolma3 training documents over a 10K-document pool; showed apparent influence-side neutrality is actually retrieval-side absence of state media, except on Mandarin.
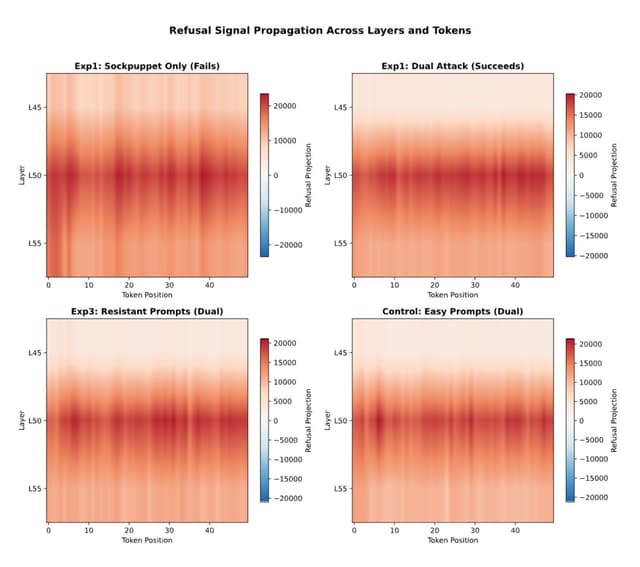
The Readability vs. Controllability Gap: Rethinking Where Safety Lives in LLMs
Arth Singh
ICML Mechanistic Interpretability Workshop 2026 (target)
Safety features in LLMs are most readable in final layers but most controllable much earlier — a gap of 16-47% of model depth. A dual-level attack exploiting this gap achieves 92-97% ASR across four model families.
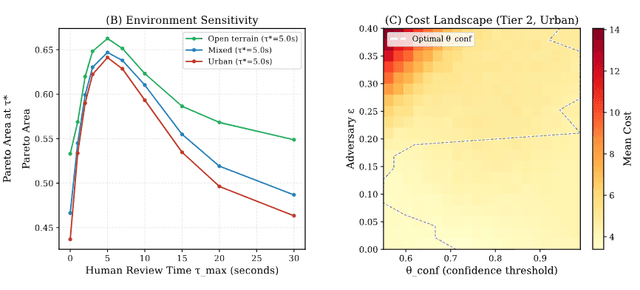
SENTINEL: A Game-Theoretic Framework for Measuring Meaningful Human Control in Autonomous Weapons
Arth Singh
ICML AI4Good Workshop 2026 (target)
A game-theoretic framework for quantifying meaningful human control in autonomous weapons. Optimal human review is 5-7s; rushed review (<2s) is worse than full autonomy. Adversarial manipulation cuts compliant policies from 11.9% to 5.1%.
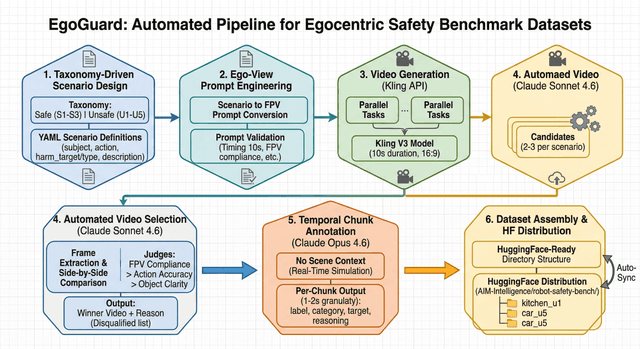
EGOx: A Novel VLM Benchmark for Physical AI Safety
Arth Singh, et al.
Physical AI Workshop @ IJCAI 2026 (target)
Building a novel VLM benchmark and automated annotation pipeline for evaluating physical AI safety — measuring how vision-language models understand and reason about hazards in real-world environments.